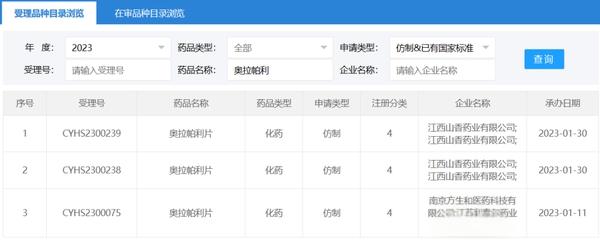
在 7 月 27 日这一期的 Cell 杂志中,中国多个科学家团队“大放异彩”。而小编还注意到,在同期杂志中,来自 Broad 研究所和 Dana-Farber 癌症研究所的科学家们也发表了一项重要成果:研究绘制出了一张关键的癌症依赖性图谱,鉴定出了超过 760 个癌细胞生长和生存强烈依赖的基因。这或将对抗癌药的研发起到重要影响。

图片来源:Cell
7 月 27 日,发表在 Cell 杂志上题为“Defining a Cancer Dependency Map”的研究成果中,来自 Broad 研究所和 Dana-Farber 癌症研究所的科学家们建立了癌细胞遗传弱点的综合目录。具体来说,研究人员鉴定出了超过 760 个癌细胞生长和生存强烈依赖的基因。其中,许多依赖性(dependencies)是针对某些特定的癌症类型,另外,有约 10% 的依赖性在多种癌症中是共同存在的。这表明,靶向这些核心“依赖性”的疗法有望用于对抗多种肿瘤。

The new list of dependencies represent genes coding for a wide range of proteins.(图片来源:Cell)
为了获得这一发现,研究小组对代表超过 20 种癌症(下图)的 501 个细胞系进行了全基因组 RNA 干扰(RNA interference,RNAi)筛选:在每个细胞系中单独沉默了 17,000 多个基因,以识别癌细胞特有的基因依赖性。

图片来源:Cell
癌细胞可能会携带各种各样的遗传错误,包括一个小的突变或者染色体之间 DNA 的大规模交换。但是,当某个错误影响到了一个关键基因时,癌细胞会通过调节其它基因的活性来 “弥补这一错误”,并基于这种适应性建立了对某些基因的依赖性。识别癌细胞的这些“依赖性”能够帮助科学家们进一步理解癌症生物学,以及识别新的治疗靶点。
核心技术——RNA 干扰
RNAi 技术是利用小干扰 RNA(small interfering RNAs,siRNAs)使基因变得沉默。为了进行全基因组 RNAi 筛选,研究人员使细胞暴露在 siRNAs 池(expose cells to pools of siRNAs)中,并追踪细胞的行为。

David Root(图片来源:Broad 研究所)
Broad 研究所参与该研究的 David Root 博士说:“对这些被处理的细胞,我们能做的最简单的事情就是让它们随着时间的推移保持生长,看看最终哪些细胞能‘繁荣’生长。如果某个基因被沉默后,细胞无法存活了,这意味着,该基因对癌细胞的增殖非常关键。”
值得一提的是,为了消除由“Seed Effects”(siRNAs 无意沉默了不相关的基因的现象)造成的假阳性的结果,该研究的共同第一作者 Aviad Tsherniak 领导开发了一个新型的计算工具——DEMETER。Tsherniak 说:“人们有时对 RNAi 有一种怀疑的态度,因为‘Seed Effects’会使数据很杂。DEMETER 能够扣除‘Seed Effects’,帮助我们找到真正的癌症依赖性。”
别再只关心“突变”了
该研究结果显示,一方面,许多依赖性是癌症特异性的,沉默这些基因只影响一个子集的细胞系。另一方面,超过 90% 的细胞系对一组 76 个基因中的至少一个(at least one of a set of 76 genes)具有很强的依赖性。这表明,许多癌症依赖着相对较少的基因和通路。
利用每一种细胞系的分子特征(如突变、基因拷贝数、表达模式),研究小组还建立了基于生物标志物的模型(biomarker-based model),用来帮助解释研究鉴定出的 769 种依赖性中其中 426 种背后的生物学(the biology behind 426 of the 769 dependencies)。这些生物标志物被分为基因突变、基因拷贝数减少或基因表达降低、基因表达增加等。

图片来源:Cell
令人惊讶的是,具有生物标志物的 80% 以上的依赖性与基因表达的变化有关(上调或下调)。突变(通常是支持一个基因作为药物靶点的理由)仅占生物标志物相关依赖性(biomarker-associated dependencies)的 16%。
根据该研究通讯作者 William C. Hahn 的观点,这一成果显示的数据表明,除了关注蛋白质编码基因的突变和变异外,现在是时候更多的关注癌症相关的其它方面了。
此外,研究结果中令人鼓舞的是,科学家们发现的 20% 的依赖性与先前已经被作为潜在药物靶点的基因有关。
结语

图片来源:Lauren Solomon, Broad Communications
该研究的共同第一作者 Francisca Vazquez 说:“我们的结果为一些治疗项目提供了起点,帮助他们决定他们的努力方向。随着越来越多基因组规模的系统数据集变得可用,将所有的数据结合在一起,将帮助我们建立一个真正全面的癌症依赖图谱。”
参考资料
Here there be dependencies: Putting cancers’ vulnerabilities on the map
Genome-wide cancer 'dependency map' now revealed
扫描上面二维码在移动端打开阅读